



Is It Worth Paying A Yearly Fee For Software Updates?
Introduction: What This Blogpost Is About
At Kepler Vision Technologies, we develop artificial intelligence that helps hospitals, elderly care facilities, and mental care facilities look after residents’ well-being. If a resident needs help, our software sends an alarm to the caregiver’s mobile phone.
We license the software on a yearly subscription basis rather than one-off payments. The recurring fees entitle customers to software updates. What do customers get out of the software updates? Does the software really get better over time?
The short answer: yes, it does. Our software improves continuously. The updates are worth paying for: We recently added the recognition of lying positions to our software to prevent bed sores. The same functionality allows for the recognition of restlessness in bed. Those are visible, tangible improvements.
However, much more work goes into invisible improvements, where we improve the recognition quality of our software. These improvements are less tangible, but they do exist, and they are significant. The neural network model updates involve expensive computational efforts in training and verification. The improvements are also included in our software updates. This article focuses on those invisible improvements.
In the remainder of this article:
- First, I will explain how the standard metric for assessing quality improvements is saturated for our software and why these measurements do not make sense in our case.
- Second, I will explain the metrics we use instead: the number of missed and false alarms over time.
- Third, I describe the four driving factors we use to improve our artificial intelligence.
- Fourth, I will present the result of 30 software updates in 20 months, and how our investments in software improvements pay off.
Everything discussed here refers to our Kepler Night Nurse software, which runs on-premise on AI servers. At the end, I’ll explain how these results also translate to our embedded Kepler Nurse Assist software, which runs on the Mobotix C71 sensor.
Why The Standard Metric To Assess Quality Improvement No Longer Works For Our Software
An often-used metric that expresses how well computer vision software, such as ours, works is the Average Precision. Average Precision is reported as a value between 0 and 100%. Values above 80% are considered excellent, while values below 50% indicate room for significant model improvement.
We view the calculated Average Precision as a very reliable metric. At Kepler, we compute it over hundreds of thousands of test images, which is two orders of magnitude more than in typical academic benchmarks. Our test sets, therefore, give us highly reliable numbers that represent real-world performance
When we started, our Average Precision scores were modest. But our software’s Average Precision scores quickly climbed to a whopping 99.7% in our second year and climbed further to scores exceeding 99.99%. Great news, but it means we can no longer use Average Precision as a helpful metric. Once you’re that close to 100%, the Average Precision stops being useful as a measure of progress. This is a good problem to have, but still a problem.
And frankly, Average Precision is not what caregivers care about. In conversations with nurses, I never refer to Average Precision scores. Instead, I refer to the number of missed alarms per year or the number of false alarms because this is important in a nurse’s day-to-day practice. So, in the remainder of this article, I will focus on those two practical measures.
Missed Falls: The Hardest Thing to Measure
If a resident falls but our software misses the fall, this is called a false negative. A missed alarm is extremely difficult for an artificial intelligence software company to identify. We need help from the software users, that is, from the caregivers, to tell us about them.
At Kepler, we measure false negatives by asking the care institutes to let us know when a resident falls, but our software misses it. To this end, we provide an online reporting tool. In the rare case of a missed alarm, we will access the video and add the missed fall to our training data. Once retrained, our software won’t miss the same type of fall again.
We consider the reports we get from care institutes very reliable. Caregivers are always upset if our software misses a fall (and so are we), and they are eager to tell us all about it.
False Alarms:Easier To Spot
A false alarm, or a false positive, is relatively easy to detect. To understand how many false positives our software generates, we use two mechanisms:
- Manual Quality Assurance. When a new care organization starts using our software, we always ask for permission for quality assurance. When our software generates alarms, we review them to see if the alarm was correct. These metrics are very reliable.
- We also use the online reporting tool described above for reporting false negatives. The occurrences of false positives are less emotional than false negatives. I will report on the numbers later on, but I believe only a fraction of the false positives are reported to us. This is not our most reliable metric, but it still indicates whether our software quality has changed for the better or for the worse.
The Four Drivers For AI Improvement
Over a 20-month period, from January 2024 until September 2025, we took several major steps to improve our software:
- Collected more hours of video, manually analyzed them, and annotated mistakes, which increased the training data by 16%.
- Trained new neural networks using this data. In total, we did so 39 times.
- Released 30 software updates incorporating these models and architectures.
- Changed new neural network architecture. There were three of these in total, with one in particular (November 2024) showing a clear performance boost, as shown in Figure 2.

The 16% increase in our training data is quite modest. In the past years, we have focused on collecting only the special cases: the outliers and missed falls. Adding them to our training data prevents us from missing them again. It also means the size of our training set does not grow so dramatically anymore, which, perhaps counterintuitively, is a good thing. As Peter Norvig, the former Director of Research and Search Quality at Google, famously said, “Better data beats more data.”
Our model update strategy is thus entirely quality-driven. When we connect new smart sensors at new care organizations, and we spot lower-than-expected results, we retrain our neural network models accordingly.
The Results: Fewer Missed And False Alarms
Let’s start with the most important result: the impact on missed falls (false negatives). Figure 1 plots the number of reports by caregivers stating our software missed a fall.
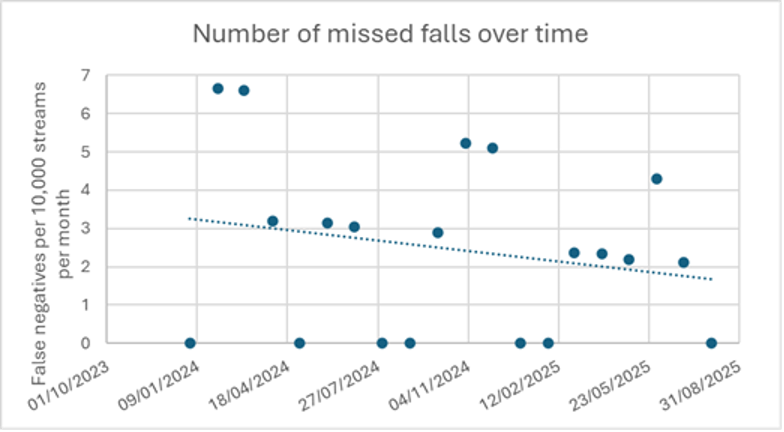
The graph shows that in 20 months, the number of missed falls was reduced by 44%, which is a significant reduction:
- Two years ago: Our customers reported a little over 3 missed falls per 10,000 sensors per month. This translates to 1 missed fall per 277 streams.
- Now: A little less than 2 missed falls per 10,000 sensors per month. That translates to 1 missed fall per 416 streams per year.
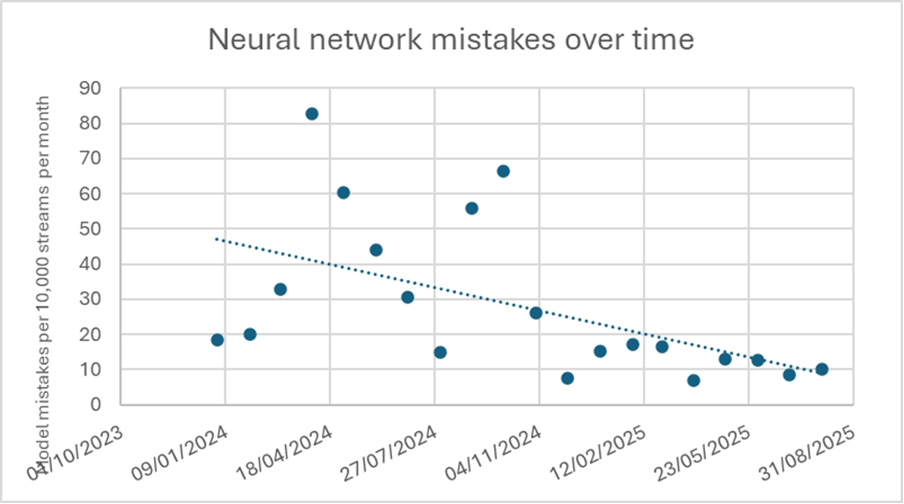
Using the same reporting mechanism, Figure 2 shows the number of neural network mistakes. These are not just fall alarms but also include other alarms such as “sitting on the edge of a bed,” “out of bed,” “out of room,” and so on. The total number of false alarms for all these detections decreased by almost 50% over a one-year period.
We have a second metric for the false positives, which comes from our own Quality Assurance process we apply to newly connected smart sensors. Here, the outcome over 12 months from March 2024 until March 2025. The time between a false fall alarm decreased from 72 days to one false alarm per 148 days. Again, this confirms the almost 50% performance increase.

How Reliable Are These Statistics, And Do They Apply To Our Embedded Kepler Nurse Assist Software?
All the results in this article apply to the Kepler Night Nurse software, which runs on-premise on AI servers. The differences and similarities with the Kepler Nurse Assist software, which runs embedded, are as follows:
- Both versions are available as a subscription. For Nurse Assist, this is called the Software Update Assurance.
- For the server version, the Kepler engineers are responsible for software updates. For the embedded version, the system integrator installs these
- The available memory and compute power on an AI server is far greater than what is available on a camera. Hence, the neural networks we can run on the camera are different from the ones we run on server. However, we train the neural networks on the exact same datasets. The performance increases described for the server version will also extend to the camera version. The absolute will differ, but the relative performance gains carry over.
A few caveats:
- The R-Square metrics are low when you consider how well the measurements in Figures 1 and 2 fit a line. Still, the fitted line is the only reliable way to infer a trend.
- For both figures 1 and 2, it could be that nurses were sometimes too busy to report. However, we still believe that the measurements for the missed falls are reliable. Nurses are eager and motivated to let us know if our software fails.
- Some new installations of our software process video streams from very low-quality sensors. This may have hurt our statistics; our software critically depends on high-quality sensors.
Conclusion: Software Improvements Pay Off
So, does our software improve over time? Absolutely.
- Two years ago: our customers reported 1 missed fall per 277 streams yearly.
- Now: our customers report 1 per 416 streams.
This is a significant improvement. So, if you have an elderly care facility with 416 residents, our software will miss one fall per year. And we’re not stopping here. We’ll keep collecting data, upgrading our neural networks, and rolling out new updates. All with the aim of keeping customers’ patients safe.
This article appeared first on LinkedIn; here is the link.