


Is het de moeite waard om jaarlijks te betalen voor software updates
Introductie: Waar gaat deze blog over?
Bij Kepler Vision Technologies ontwikkelen we kunstmatige intelligentie die ziekenhuizen, verpleeghuizen en GGZ-instellingen helpt om het welzijn van bewoners te bewaken. Wanneer een bewoner hulp nodig heeft, stuurt onze software direct een alarm naar de smartphone van de zorgmedewerker.
We licentiëren onze software via een jaarlijks abonnement in plaats van een eenmalige betaling. De terugkerende kosten geven klanten recht op software-updates. Wat leveren die updates hen precies op? Wordt de software daadwerkelijk beter met de tijd?
Het korte antwoord: ja, absoluut. Onze software verbetert continu. De updates zijn de investering waard: zo hebben we onlangs de herkenning van ligposities toegevoegd om doorligwonden te voorkomen. Diezelfde functionaliteit maakt het mogelijk om onrust in bed te detecteren. Dat zijn zichtbare, tastbare verbeteringen.
Maar er gebeurt nóg veel meer op het gebied van niet-zichtbare verbeteringen, waarbij we de herkenningskwaliteit van onze software verfijnen. Deze verbeteringen zijn minder tastbaar, maar ze bestaan wel degelijk en ze zijn aanzienlijk. Het updaten van onze neurale netwerken vereist kostbare rekenkracht voor training en verificatie. Ook deze verbeteringen zitten in onze software-updates. Deze blog richt zich vooral op die onzichtbare verbeteringen.
In de rest van dit artikel:
- Leg ik uit waarom de standaardmetriek voor kwaliteitsverbetering bij onze software niet meer werkt.
- Bespreek ik de alternatieve metrics die we gebruiken: het aantal gemiste en valse alarmen over tijd.
- Beschrijf ik de vier factoren die de verbetering van onze AI aandrijven. Laat ik zien wat 30 software-updates in 20 maanden hebben opgeleverd, en hoe onze investeringen zich uitbetalen.
Alles wat hier wordt besproken, gaat over onze Kepler Night Nurse-software, die on-premise draait op AI-servers. Tot slot leg ik uit hoe deze resultaten ook gelden voor onze embedded Kepler Nurse Assist-software, die draait op de Mobotix C71-sensor.
Waarom de standaardmetriek voor kwallitieitsmeting niet meer werkt voor onze software
Een veelgebruikte metriek om te bepalen hoe goed computer vision-software werkt, is de Average Precision. Deze wordt weergegeven als een waarde tussen 0 en 100%. Waarden boven 80% gelden als uitstekend, waarden onder 50% duiden op ruimte voor verbetering.
Wij beschouwen Average Precision als een zeer betrouwbare maat. Bij Kepler berekenen we deze over honderdduizenden testbeelden—twee ordes groter dan gebruikelijk in academische benchmarks. Onze testsets leveren daardoor zeer betrouwbare cijfers die de praktijk accuraat weerspiegelen.
In het begin waren onze Average Precision-scores bescheiden. Maar al snel stegen ze naar 99,7% in ons tweede jaar, en vervolgens naar waarden boven 99,99%. Fantastisch nieuws—maar hierdoor is Average Precision niet langer een bruikbare maat. Zodra je zó dicht bij 100% zit, houdt de metriek op relevant te zijn. Een luxeprobleem, maar toch een probleem.
En eerlijk gezegd: zorgmedewerkers geven niets om Average Precision-scores. In gesprekken met verpleegkundigen heb ik het er nooit over. Wat voor hen telt, is het aantal gemiste alarmen per jaar en het aantal valse alarmen. Daarom richt ik me in de rest van dit artikel op deze twee praktische metingen.
Gemiste vallen: het moeilijktse om te meten
Wanneer een bewoner valt maar onze software dit niet detecteert, spreken we van een false negative. Een gemist alarm is voor een AI-bedrijf zeer moeilijk om zelf te ontdekken. Hiervoor zijn we afhankelijk van de gebruikers van de software, de zorgmedewerkers.
Bij Kepler meten we false negatives door zorginstellingen actief te vragen om elke val die de software mist aan ons te melden. Hiervoor bieden we een online meldtool. In het zeldzame geval dat een val wordt gemist, bekijken we de video en voegen we het incident toe aan onze trainingsdata. Na hertraining zal onze software dit type val niet meer missen.
We beschouwen deze meldingen als uiterst betrouwbaar. Zorgmedewerkers zijn altijd gealarmeerd wanneer een val wordt gemist (wij ook), en ze melden dit graag.
Valse alarmen: Moeilijker te signaleren
Een vals alarm, of false positive, is eenvoudiger te detecteren. Om te bepalen hoeveel valse alarmen onze software geeft, gebruiken we twee methoden:
- Handmatige kwaliteitscontrole. Wanneer een nieuwe zorgorganisatie start met onze software, vragen we vrijwel altijd toestemming om mee te kijken. We bekijken dan of elk gegenereerd alarm terecht was. Deze cijfers zijn zeer betrouwbaar.
- De eerder genoemde online meldtool.Valse alarmen worden minder emotioneel ervaren dan gemiste alarmen. Zoals ik later zal toelichten, vermoed ik dat slechts een fractie van de valse alarmen wordt gemeld. Het is dus niet onze betrouwbaarste metriek, maar het geeft wel een indicatie van trends: gaat de software vooruit of achteruit?
De vier aandrijvers voor AI verbetering
Gedurende een periode van 20 maanden, van januari 2024 tot september 2025, hebben we grote stappen gezet om onze software te verbeteren:
- We verzamelden meer uren aan video, analyseerden deze handmatig en labelden fouten—met als resultaat 16% meer trainingsdata.
- We trainden nieuwe neurale netwerken met deze data—39 keer in totaal.
- We brachten 30 software-updates uit waarin deze modellen en architecturen waren verwerkt.
- We introduceerden drie nieuwe netwerkarchitecturen, waarvan er één (november 2024) een duidelijk zichtbare kwaliteitsboost opleverde (zie Figuur 2).

De toename van 16% in onze trainingsdata is vrij bescheiden. In de afgelopen jaren hebben we ons gericht op het verzamelen van uitsluitend de bijzondere gevallen: de outliers en de gemiste vallen. Door deze aan onze trainingsdata toe te voegen, voorkomen we dat we dergelijke situaties opnieuw missen. Dit betekent ook dat de omvang van onze dataset niet meer spectaculair groeit wat misschien contra intuïtief klinkt, maar juist positief is. Zoals Peter Norvig, voormalig Director of Research and Search Quality bij Google, ooit treffend zei: “Better data beats more data.”
Onze strategie voor modelupdates is dan ook volledig kwaliteitsgedreven. Wanneer we nieuwe slimme sensoren aansluiten bij nieuwe zorgorganisaties en we lagere dan verwachte prestaties zien, trainen we onze neurale netwerken opnieuw op basis van die feedback.
De resultaten: minder gemiste en valse alarmen
Laten we beginnen met het belangrijkste resultaat: de impact op gemiste vallen (false negatives). Figuur 1 toont het aantal meldingen van zorgmedewerkers waarin staat dat onze software een val heeft gemist.
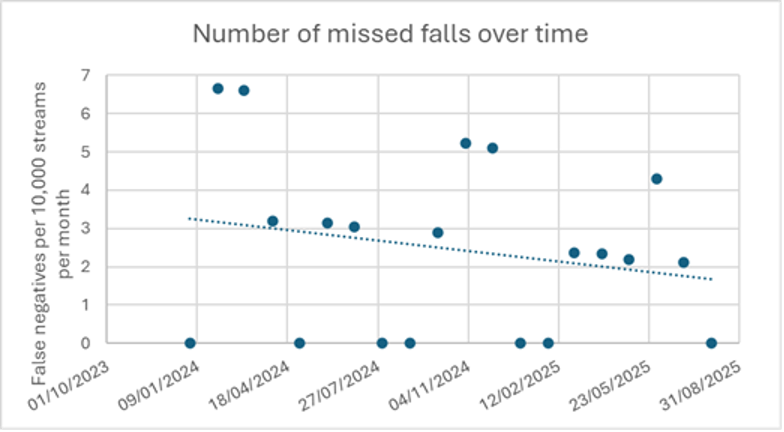
De grafiek laat zien dat het aantal gemiste vallen in 20 maanden tijd met 44% is gedaald, een aanzienlijke verbetering:
- Twee jaar geleden: onze klanten rapporteerden iets meer dan 3 gemiste vallen per 10.000 sensoren per maand. Dit komt neer op 1 gemiste val per 277 streams.
- Nu: iets minder dan 2 gemiste vallen per 10.000 sensoren per maand. Dit komt neer op 1 gemiste val per 416 streams per jaar.
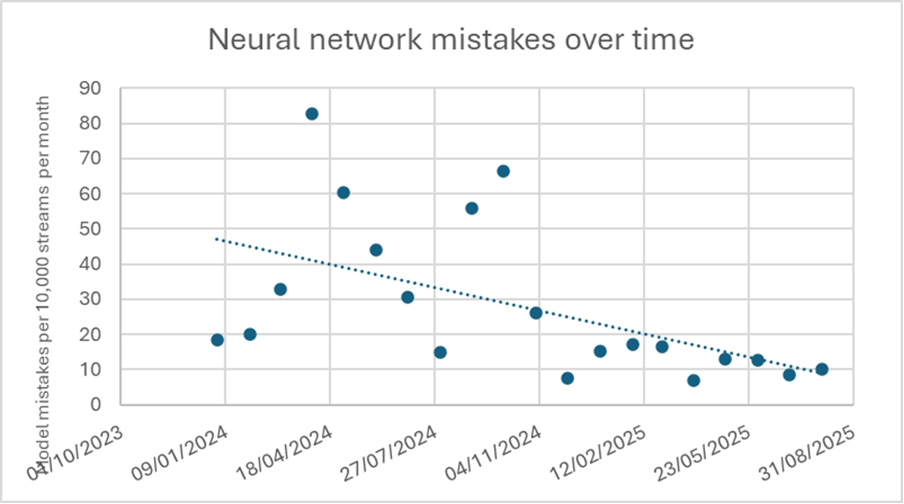
Met hetzelfde registratiemechanisme laat Figuur 2 het aantal fouten van het neurale netwerk zien. Dit betreft niet alleen valalarmen, maar ook andere alarmen zoals “op de rand van het bed zitten”, “uit bed”, “uit de kamer”, enzovoort. Het totaal aantal valse alarmen voor al deze detecties is in één jaar tijd met bijna 50% gedaald.
We hebben daarnaast een tweede metriek voor de valse alarmen, afkomstig uit onze eigen Quality Assurance-procedure die we toepassen op nieuw aangesloten slimme sensoren. De resultaten over 12 maanden, van maart 2024 tot maart 2025, laten het volgende zien: de tijd tussen twee valse valalarmen nam toe van 1 vals alarm per 72 dagen naar 1 vals alarm per 148 dagen. Ook dit bevestigt de bijna 50% prestatieverbetering.

Hoe betrouwbaar zijn deze statistieken, en gelden ze ook voor onze embedded Kepler Nurse Assist software?
Alle resultaten in dit artikel hebben betrekking op de Kepler Night Nurse-software, die on-premise draait op AI-servers. De verschillen en overeenkomsten met de embedded Kepler Nurse Assist-software zijn als volgt:
- Beide versies zijn verkrijgbaar via een abonnementsmodel. Voor Nurse Assist noemen we dit de Software Update Assurance.
- Bij de serverversie zijn de Kepler-engineers verantwoordelijk voor de software-updates. Bij de embedded versie worden de updates geïnstalleerd door de systeemintegrator.
- De beschikbare geheugen- en rekenkracht op een AI-server is aanzienlijk groter dan wat beschikbaar is op een camera. Daarom draaien er op de camera andere neurale netwerken dan op de server. Maar: we trainen alle neurale netwerken op exact dezelfde datasets. Hierdoor gelden de prestatieverbeteringen die we voor de serverversie meten óók voor de camera-versie. De absolute prestaties verschillen, maar de relatieve verbeteringen worden wél doorgegeven.
Een paar kantekeningen:
- De R²-waarden zijn laag wanneer je kijkt naar hoe goed de metingen in Figuur 1 en 2 op een rechte lijn passen. Toch is een trendlijn de enige betrouwbare manier om ontwikkelingen over tijd af te leiden.
- Het is mogelijk dat verpleegkundigen in sommige gevallen te druk waren om een melding te doen. Toch geloven we dat de metingen van gemiste vallen zeer betrouwbaar zijn; verpleegkundigen zijn gemotiveerd om het direct te melden wanneer onze software faalt.
- Sommige nieuwe installaties gebruiken videostreams afkomstig van sensoren van zeer lage kwaliteit. Dit kan onze statistieken negatief beïnvloed hebben, omdat onze software sterk afhankelijk is van hoogwaardige sensoren.
Conclusie: Softwareverbeteringen betalen zich uit
Dus: verbetert onze software met de tijd? Zonder twijfel.
- Twee jaar geleden: 1 gemiste val per 277 streams per jaar.
- Nu: 1 gemiste val per 416 streams per jaar.
Dat is een aanzienlijke verbetering. Concreet betekent dit: in een zorginstelling met 416 bewoners zal onze software gemiddeld één val per jaar missen. En daar laten we het niet bij. We blijven data verzamelen, onze neurale netwerken verbeteren en nieuwe updates uitrollen. Alles met één doel: de veiligheid van bewoners en patiënten waarborgen.
Dit artikel is eerst op LinkedIn verschenen; here is the link.